
Privacy is a choice — Take it
In den vergangenen Jahren wurden digitale Geräte wie Computer oder Handys immer mehr zu einem täglichen Begleiter. Ein Begleiter der Einsicht in unser Leben hat wie kein anderer. Wir tragen unsere Handys immer mit uns, zu Hause, bei der Arbeit, manche sogar auf der Toilette. Die Kommunikation mit Familie und Freunden findet immer mehr auf diesen digitalen Geräten statt . Dieser Begleiter hat uns klare Vorteile gebracht, wie neue Wege, um neue Menschen kennenzulernen oder mit alten Freunden im Kontakt zu bleiben.
Allerdings sind diese digitalen Begleiter ein zweischneidiges Schwert, die Vorteile, die jeder kennt einerseits und die Risiken an der eigenen Privatsphäre andererseits. Diese Arbeit wird sich damit auseinandersetzen, was die Risiken der modernen Technologien sind und was man lieber nicht mit jedem teilt. Es wird auch auf die technologische Seite der Privatsphäre geschaut, um aufzuzeigen, wie das Tracking funktioniert. Die gesellschaftlichen Aspekte werden, um einen Kontext für die Problemstellung zu geben, auch noch beleuchtet. Abschliessend wird es in dieser Arbeit Einblicke geben, wie man seine eigene Privatsphäre besser schützen kann, um ungewollte Blicke fernzuhalten.
Es ist wichtig zu verstehen, was die Risiken an der aktuellen Datenpolitik sind und weshalb man besonders beim Thema der Datenspeicherung weit in die Zukunft schauen muss. Das Verständnis aufzubauen, welche Daten gesammelt werden und was daraus entstehen kann, hilft zukünftig bessere Entscheidungen zu treffen und sich für eine bessere digitale Zukunft zu rüsten. Es ist aber auch wichtig zu wissen, wie man sich über die Privatsphäre Regeln eines Services informieren und falls nötig, wie man Alternativen finden kann.
Vor einigen Monaten habe ich mich auf den Weg begeben, meine Daten immer mehr zu mir zu holen. Dies habe ich gemacht, da ich nicht will, dass jeder sehr einfach Informationen über mich erfahren kann. Alles hat damit gestartet, dass ich meinen Vor- und Nachnamen auf Google gesucht habe und erstaunt war, dass es so viele Resultate gibt, die sehr viel über mich aussagen. Ich habe mich dann entschlossen diese Liste durchzugehen und Accounts, die ich nicht mehr benötige zu deaktivieren oder zu löschen. Seither ist das Thema um die Privatsphäre im Onlinedschungel ein stetiger Begleiter in meinem Alltag. Ich versuche persönliche Informationen aus dem Internet zu halten und nur das zu teilen, das ich au aktiv teilen will.
Diese Arbeit schreibe ich, um ein tieferes Verständnis zu erhalten, was hinter dem Begriff der Privatsphäre steckt und weshalb gefühlt wenige Menschen sich um ihre Privatsphäre kümmern und weniger persönliche Informationen im Internet teilen. Zusätzlich möchte ich erfahren, wie viele Daten Google denn wirklich trackt und wie es um andere Services ausschaut. Ich werde in dieser Arbeit auch die Möglichkeit erhalten, mein bestehendes Wissen herauszufordern.
In dieser Arbeit werde ich zu meinen Forschungsfragen recherchieren, um einen groben Überblick über das Thema zu erhalten. Relevante Unterthemen werden dann weiter vertieft, um in die Arbeit einzufliessen. Um externe Meinungen und Gedanken zu erhalten, werde ich ein Interview machen. Das Interview sollte die Perspektive von jemandem aufzeigen, der nicht tief im Thema steckt wie ich und sich im besten Falle noch keine grossen Gedanken dazu gemacht hat. Um Informationen zu visualisieren, wird während dieser Arbeit ein Data Science Projekt erarbeitet, das gewisse Grafiken oder andere Informationen liefern sollte. Meine Erfahrungen werde ich auch in der Arbeit teilen, um den Umstieg für andere leichter zu gestalten.
Neue Apps und Services wollen immer mehr über uns wissen. Neue Features benötigen weitere Zugriffe auf unseren Handys oder unsere Bilder werden gescannt, um Kinderpornografie zu bekämpfen .
In diesem Kapitel wird es darum gehen, die Risiken aufzuzeigen, die entstehen können, wenn immer mehr Daten über uns gesammelt werden. Es wird auch aufgezeigt, welche Informationen man schützen will und weshalb.
In der Diskussion zur Privatsphäre kommt oft der Satz, dass man ja nichts zu verbergen habe und daher kein Problem damit hat, wenn andere Informationen über einen sammeln.
In seinem Paper macht ein gutes Argument, dass jeder etwas zu verbergen hat oder zumindest nicht mit jedem teilen möchte. Die meisten Menschen haben etwa Vorhänge an ihren Fenstern, um vor ungewollten Blicken zu schützen, da keiner in den intimsten Momenten beobachtet werden will. Dieses völlig natürliche Verhalten widerspricht der Aussage, dass man nichts zu verbergen habe.
Auf der anderen Seite schreibt darüber, dass es völlig legitim ist, das Recht auf Privatsphäre zu verletzten, um grössere gesellschaftliche Interessen wie Sicherheit zu gewährleisten. Mit diesem Argument kann man zumindest bis zu einem gewissen Grad das Tracking und die Datenspeicherung von Regierungen legitimieren.
Da der Fokus dieser Arbeit primär auf privaten Firmen und deren Aktivitäten liegt, kann man jedoch schlecht mit einem grösseren gesellschaftlichen Interesse argumentieren.
Um die Frage zu beantworten, welche Informationen man vor privaten Firmen schützen sollte, kann man sich eine simple Frage stellen. Ist es möglich, aus den Informationen einen finanziellen Vorteil zu gewinnen? Denn am Ende haben Firmen nur ein Ziel, Umsatz und Gewinn zu generieren.
Um das folgende Beispiel zu verstehen, muss erst der Begriff der Gesundheitsdaten definiert werden. In diesem Kontext werden alle Informationen, die einen Rückschluss auf den Gesundheitszustand eines Nutzers erlauben als Gesundheitsdaten eingestuft. Das beinhaltet, was der Nutzer konsumiert oder wie viele Schritte pro Tag gemacht werden.
Um die Problematik zu veranschaulichen, ein Beispiel, wie sich die Sammlung und Verarbeitung von Daten auswirken kann.
Auf einer Seite befindet sich James, er ist 19 Jahre alt und arbeitet als Labortechniker bei einer grossen Schweizer Firma. In seiner Freizeit geht er gerne wandern oder ist im Fitnessstudio. In den vergangenen Monaten hat sich James mehr mit seiner Ernährung auseinandersetzt und lebt nun seit ca. 5 Monaten vegan. Er konsumiert keine Drogen, auch kein Nikotin oder Alkohol. Seine Erfahrungen und Aktivitäten teilt James auf einem Instagram Account.
Auf der anderen Seite ist Andrew, er ist 21 Jahre alt und arbeitet als Kassierer bei einem Supermarkt. In seiner Freizeit geniest er seine Zeit im Casino mit seinen Freunden oder bei einem guten Essen mit ein paar Drinks und viel Fleisch. Andrew startete mit 17 Zigaretten zu rauchen und gönnt sich regelmässig einen Joint. Er ist auch gerne schnell unterwegs, wenn er mit seinem Motorrad über die Pässe der Schweizer Alpen fährt. Andrew’s Leben und Ausflüge sind auf seinem TikTok Account dokumentiert.
Als Krankenversicherung sind diese beiden, zugegeben extremen Profile, sehr interessant. Sie geben Einblicke in das Leben von Kunden und ermöglichen es der Krankenversicherung zu bestimmen, wie hoch das Risiko ist, dass eine Person überdurchschnittliche Leistungen beziehen wird. Obwohl James und Andrew die Daten nicht aktiv mit der Krankenversicherung geteilt haben, ermöglicht dies eine Einschätzung, die wahrscheinlich zufolge hat, dass Andrew ein grösseres Risiko ist als James.
Um die gewonnenen Erkenntnisse finanziell zu nutzen, könnte man Andrew die Versicherung entweder komplett verwehren oder zu einem viel höheren Preis als James bezahlen würde.
In dieser Geschichte gibt es viele Probleme. Ein sehr zentrales Problem ist das eigentliche Posten der Informationen auf Plattformen wie Instagram oder TikTok, ohne die Konsequenzen zuvor abzuwägen. Man sollte jegliche Konsequenzen in Bezug auf die Privatsphäre kennen, bevor man einen Post auf Social-Media-Plattformen macht. Man kann aber auch damit argumentieren, dass die Nutzung der Daten von der Krankenversicherung nicht ethisch ist. Dass aber jede Firma ethisch handelt, ist meiner Meinung nach eine absolute Utopie.
Auf der technologischen Seite gibt es mehrere Level, einen Nutzer zu tracken. Dieses Kapitel wird sich mit diesen Levels auseinandersetzen und aufzeigen, welche Informationen gespeichert werden und weshalb das aktuelle Vorgehen oft problematisch ist. Zum Schluss wird noch aufgezeigt, welche Alternativen es gibt, um Daten zu erhalten, ohne die Privatsphäre einzelner Nutzer zu verletzen.
Ein wichtiges Konzept in der Diskussion um die Privatsphäre ist, wie einfach Informationen kombiniert werden können, um ein grösseres Bild zu erhalten. Informationen, die allein bedeutungslos sind, können kombiniert zu Daten werden, die nicht mehr bedeutungslos sind. Aktuell werden Telemetriedaten an Firmen mit langlebigen Identifier wie die IMEI Nummer beim Handy 1. Das bedeutet, dass alle gesammelten Daten über die Lebenszeit von einem Handy später noch verbunden und ausgewertet werden können.
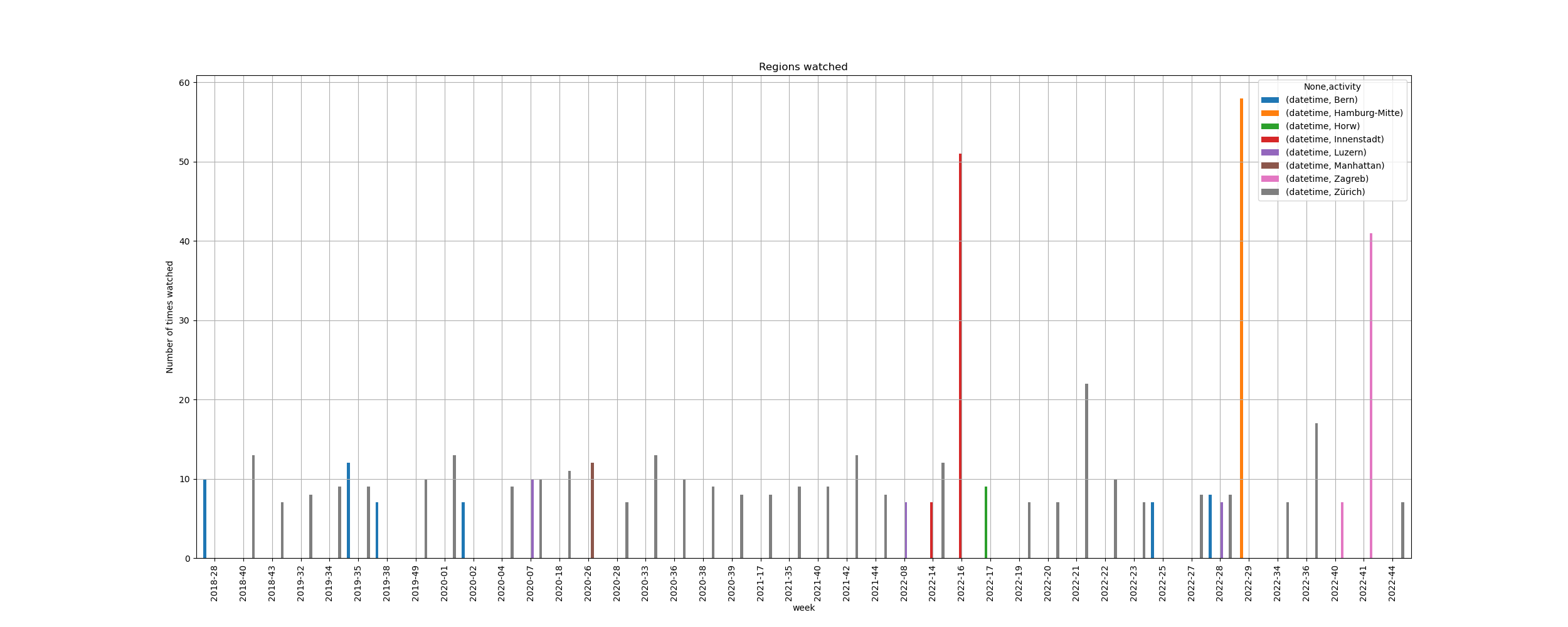
Die Grafiken2 zeigen zwei Sets an Informationen, die zusammen Cross Linked werden können. Die erste Grafik zeigt, wie oft Google Maps geöffnet wurde in jeder Woche. Die zweite Grafik zeigt, welche Regionen am meisten angeschaut wurden und in welcher Woche dies passiert ist.
Beide Grafiken beinhalten gewisse Anomalien oder Ausschläge, die auf irreguläres Verhalten hindeuten. Es kann viele Gründe haben, weshalb man Google Maps in einer Woche öfter nutzt. Es kann sein, dass man in dieser Woche mehr mit dem Fahrrad unterwegs war oder temporär an einem anderen Arbeitsort ist und man sich daher noch nicht gut auskennt. Es gibt auch viele Gründe, weshalb man sich für eine Region sehr stark interessiert. Jemand sucht vielleicht Aktivitäten in der Nähe für Freunde, die aus dem Ausland vorbeikommen oder man arbeitet an einer Präsentation über eine spezifische Region.
Kombiniert zeigen diese beiden Ausschläge jedoch ein ganz anderes Bild. Auf der zweiten Grafik kann man erkennen, dass die Region um Zürich oft und regelmässig angeschaut wird. Dies kann aufzeigen, dass die Person sich oft in Zürich befindet. Durch die Regularität könnte man also mit dem Wohn- oder Arbeitsort argumentieren. Die Ausschläge auf der zweiten Grafik finden immer dann statt, wenn auch Google Maps besonders oft geöffnet wird. Es gibt viel weniger Szenarien, wo man nur 1 Woche sehr hohes Interesse in eine Region wie Hamburg oder Zagreb hat und auch vielfach Google Maps öffnet. Ein logischer Schluss, der dabei gezogen werden kann, ist, dass die Person zu diesen Zeiten entweder beruflich oder privat in diesen Städten war.
Dieses Beispiel hat gezeigt, dass Informationen in einem Vakuum nutzlos sein können, in einer Kombination aber wertvolle Einblicke ins Privatleben einer Person bieten können.
Dieses Kapitel beschäftigt sich mit dem Tracking auf der Ebene des Betriebssystems, konkret das Betriebssystem unserer Handys. Unter Betriebssystem wird dabei jegliche Software gezählt, die der Nutzer nicht deinstallieren und/oder deaktivieren können.
Es gibt zwei Betriebssysteme im Handymarkt, zum einen Appel’s iOS und Google’s Android. Android wird in verschiedenen Versionen oder Distributionen angeboten, welche die Hardwarehersteller3 selbst anpassen und weiterentwickeln. Dadurch ist es nicht möglich, alle Android-Geräte immer gleichzubehandeln, wenn es um die Privatsphäre geht.
Etwas, das aber alle grossen Hersteller gemeinsam haben, sind die vorinstallierten Google Services. Das sind Apps von Google, die im Hintergrund laufen, die meisten Nutzer haben daher auch noch nie aktiv, mit den Google Services interagiert. Ohne die Google Services würden z. B. viele Banking-Apps oder Benachrichtigungen nicht funktionieren. Das Problem mit den Google Services ist, dass man ihre Berechtigungen nicht einschränken kann oder sie gar deinstallieren. Die kommenden Kapitel werden sich damit beschäftigen, weshalb dies eine Problematik darstellt.
Um die Funktion von Android zu verstehen, muss man zuerst zwischen Betriebssystem und Kernel unterscheiden. Beides wird von Google entwickelt und läuft unter demselben Namen. Wobei das Betriebssystem auf dem Kernel aufbaut. Der Android Kernel ist Open Source, das bedeutet, jeder kann ihn verwenden und weiter entwickeln. Das Resultat daraus sind viele Distributionen mit ihren eigenen Features und Möglichkeiten. Dieses Kapitel wird sich mit Distributionen von Samsung, Xiaomi, Realme und /e/OS beschäftigen, wobei die ersten drei Distributionen von Hardwareherstellern sind. /e/OS ist ein Community-Projekt mit dem Ziel Google Services aus Android zu entfernen.
Eine Studie aus 2021 hat sich mit den Daten, die ein Handy an externe Server überträgt, auseinandergesetzt. Es wurde gefunden, dass ein Handy von z. B. Samsung Daten an Server von Google, Microsoft und LinkedIn sendet, ohne dass der Nutzer dem zugestimmt oder eine der Apps geöffnet hat. Dies passt auch zu den Privatsphäre-Regelungen, die LinkedIn hat. Sie geben an, dass sie Daten über Nutzer speichern, ohne dass diese mit dem Service interagiert haben . Es ist jedoch wichtig anzumerken, dass Google viel mehr Daten sammelt als alle anderen Firmen. 1 KB/h wird von Microsoft und LinkedIn gesammelt, Google auf der anderen Seite sendet etwa 40 KB/h an ihre Server. /e/OS auf der anderen Seite sammelt und gar keine Informationen an externe Server.
Die Frage zu beantworten, welche Daten gesammelt werden, ist nicht ganz einfach. Grund dafür ist, dass die Apps und Service die Daten verschlüsseln, bevor sie an ihre Server gesendet werden. Das bedeutet, dass man die Applikation reverse engineeren muss, um an die Inhalte zu kommen. Eine Studie aus 2021 hat jedoch bei gewissen Herstellern analysiert, welche Informationen an die externen Server gesendet werden. Xiaomi speichert zum Beispiel, wann eine App geöffnet und geschlossen wurde oder wann ein Anruf begonnen hat und wann einer geendet ist. Diese Information kann über Zeit dazu dienen, um herauszufinden, wer oft mit wem telefoniert. Was auch alle untersuchten Distributionen bis auf /e/OS sammeln, sind die installierten Apps und deren Versionen. Diese Information allein ist bereits ausreichend, um einen digitalen Fingerabdruck zu erstellen.
Die Trackingaktivitäten, die auf dem Applikationslevel passieren, sind sehr individuell und können daher nicht klar definiert werden. Gewisse Apps schützen die Privatsphäre ihrer Nutzer sehr stark. Ein Artikel der New York Times hat im August einen Artikel veröffentlicht, dass der Browser in der TikTok App die Möglichkeit hat, jegliche Aktivitäten der Nutzer zu tracken. Das beinhaltet auch die Eingaben in Passwortfeldern. Es kann zwar nicht nachgewiesen werden, ob die Aktivitäten auch an TikTok gesendet werden, die Möglichkeit allein ist jedoch bereits alarmierend. In einer solchen Situation kann man sich nur schützen, wenn man in solchen Situationen das Bewusst sein hat, wie in 5.1 beschrieben.
Ein sehr grosser Punkt, der auch noch zum Applikation-Tracking zählen kann, ist das Tracking auf Webseiten. Gewisse Services nutzen embedings 4 wie Pinterest, Twitter oder Google Ad Services, um shadow Profile 5 zu erstellen. Im Gegensatz zu Cookies können diese Profile nicht gelöscht oder abgelehnt werden, dies zeigt sich auch in einem neuen Trend weg von Cookies und hin zu Fingerprinting. Dies beschreibt das Sammeln und speichern gewisser Attribute, die kombiniert einmalig für einen Benutzer sind. Informationen, die dazu verwendet werden, können bereits besuchte Webseiten sein oder das Handymodell eines Nutzers. Auch bei Fingerprinting kann man das Tracking nicht ablehnen, da der Nutzer nie davon erfährt.
Es ist klar, dass Daten das neue Gold sind. Es ist wichtig für Services so viel Daten wie möglich zu sammeln, um ihre Produkte so gut wie möglich weiterzuentwickeln. Damit hat auch niemand ein Problem, es muss einfach in einem Rahmen passieren, der die Privatsphäre schützt. Es gibt eine Technologie oder Konzept namens DivviUp6, die genau dies ermöglicht. Es interessiert keinen, was ein spezifischer Nutzer wann macht, was man wissen will ist, was viele Nutzer wann machen. Dies macht sich DivviUp zu nutzen. Normalerweise werden Daten in einer Datenbank gespeichert, um nachher Statistiken daraus zu erstellen. Dass die Datenspeicherung mit problematisch ist, wurde in dieser Arbeit bereits ausführlich beschrieben. Bei DivviUp werden die Daten auf dem Gerät in zwei geteilt, verschlüsselt und an zwei unabhängige Server gesendet. Beide Server erstellen dann aus ihren Daten, die nicht mit anderen Informationen verbunden werden können, eine Statistik. Diese beiden Statistiken werden dann an einen dritten Server übermittelt, der die Statistiken zusammen bringt, um ein gesamtheitliches Bild zu erhalten. Dadurch hat man am Ende das gewünschte Resultat, ohne die Privatsphäre der Nutzer zu schaden.
Viele Firmen nutzten diese Technologie nicht, weil sie dadurch die Daten verlieren und nicht neue Statistiken basierend auf historischen Daten machen können.
Die Problematik besteht dabei darin, dass es nicht möglich ist, die Software zu deinstallieren, die im Hintergrund Daten sammelt. Eigentlich setzt die Gesetzgebung vor, dass man dem zustimmen muss. Deshalb existieren in der EU auch die Cookie-Banner, die wir alle kennen. Diese Regelung kann umgangen werden, indem man diese Information und die Zustimmung einholt, wenn der Nutzer das Gerät aufsetzt. Das bedeutet, als Person ohne grosses technisches Wissen hat man gewissermassen keine Change ein Leben zu leben, ohne dass Firmen wie Google oder Microsoft mehrere Megabyte an Daten täglich an ihre Server senden.
Auch im Web werden Nutzer immer mehr getrackt, was Informationen über ihr Such und Kaufverhalten bietet. In einem Interview meinte jemand zu mir, dass sie es beängstigend findet, wenn Google ihren Suchverlauf kennt.
Dieses Kapitel wird sich mit dem gesellschaftlichen Aspekt der Privatsphäre auseinandersetzen. Es soll die Frage geklärt werden, was unsere Gesellschaft unter Privatsphäre versteht und wie das Wissen um das Thema Tracking steht. In diesem Kapitel werde ich mehrheitlich meine Beobachtungen, die durch drei geführte Interviews gestützt wurden. Meine Beobachtungen limitieren sich generell auf Jugendliche und junge Erwachsene.
Ein Paper aus 2007 hat sich umfangreich mit der Definition von Privatsphäre auseinandergesetzt. Die Schwierigkeit Privatsphäre zu definieren liegt darin, dass das Konzept der Privatsphäre sehr individuell sein kann. Daher ist es nicht möglich, eine klare Definition von Privatsphäre aufzustellen. Einen Ansatz, der gewählt hat, um Privatsphäre zu definieren, bezieht sich mehrheitlich auf die Konsequenz der Verarbeitung oder Speicherung von Daten. Sollte dies eine negative Konsequenz haben können, sollte man von Daten sprechen, die aufgrund der Privatsphäre schützenswert sind. Ein weiterer Ansatz, den er in seinem Paper beleuchtet, beschreibt Privatsphäre als all die Informationen, die man nicht teilen möchte oder keine andere Person zu interessieren haben. Da kommt jedoch wider das Problem der Individualität ins Spiel.
Ich konnte beobachten, dass zwar ein Grundwissen besteht, welche Informationen das gesammelt werden. Was meistens ein Thema ist, sind die Cookies. Man ist sich bewusst, dass diese dazu dienen im Internet getrackt zu werden. Weitere Tracking Technologien sind jedoch den meisten nicht bewusst. Auch wann und welche Informationen gesammelt werden, ist vielen nicht bewusst. Was mich in den Interviews erstaunt hat, ist, dass das Bewusstsein da ist, dass auf Android mehr Daten gesammelt werden als auf iOS. Dies jedoch nicht basierend auf Nachrichten oder anderen Quellen, sondern mehrheitlich aufgrund der Nähe zu Google.
Die meisten konnten mit Begriffen wie oder Fingerprinting nichts anfangen. Dies kann man auf fehlende Bildung in diesem Bereich zurückführen.
Die JAMES Studie () hat sich unter anderem mit dem Verhalten von Jugendlichen in Bezug auf die Privatsphäre Einstellungen beschäftigt. Dabei haben rund 60 % der Befragten angegeben, dass sie ihre Privatsphäre durch entsprechende Einstellungen schützen wollten. Lediglich 28 % der Befragten machen sich Sorgen um die Sichtbarkeit persönlicher Informationen in den sozialen Netzwerken.
Dies zeigt mir, dass das Interesse für Privatsphäre da ist, und sich ein erheblicher Teil der Jugendlichen auch Sorgen um ihre Privatsphäre macht. Diese Erkenntnis haben auch meine Interviewpartner widergespiegelt. In den Interviews wurde auch das Thema angesprochen, wie man reagiert, wenn eine App oder Website auf Informationen wie Standort oder Kontakte zugreifen will. 2 / 3 haben da angegeben, dass sie versuchen Apps so wenig Rechte zu geben wie möglich. Grössere Einschränkungen durch Alternativen auf sich zu nehmen, sind jedoch die meisten nicht. Auch das technische Wissen um eine Alternative zum aktuellen Betriebssystem, wie in [section:android-grapheneos] beschrieben, sind die meisten nicht. Generell habe ich beobachtet, dass oft die Bequemlichkeit Nutzer daran hindert, auf eine Alternative umzusteigen, die ihre Privatsphäre besser berücksichtigen. Dies zeigt sich besonders stark bei den Chat Messengern wie WhatsApp oder Signal. Viele nutzen das, was ihr Umfeld auch nutzt, das bedeutet aber nicht, dass es die beste Option in Bezug auf die Privatsphäre ist.
Im Austausch und Recherche für diese Arbeit habe ich mich viel mit Menschen in meinem Umfeld über das Thema der Privatsphäre ausgetauscht. Oft wurde die Aussage getätigt, dass es gar keine Alternativen gibt oder dass Alternativen nicht dieselbe Qualität haben wie der Service, der aktuell genutzt wird. Besonders dem zweiten Punkt kann ich dabei sehr stark zustimmen. Es gibt jedoch auch sehr viele Alternativen, die weitestgehend dieselben Features und Funktionen bieten, z. B. . Weitere Informationen zu Alternativen sind in folgenden Kapitel: .
This chapter will provide an insight in how I protect my privacy and which techniques I use. This chapter will also contain some practical tips for everyone to follow on multiple levels. Some require no technical skill, some do more.
The most important step for protecting one’s privacy is to be aware what information should be private and how tracking is happening. This information can be vital when reducing your digital footprint.
It might be interesting to share everything on social media platforms, but regarding privacy, that’s one of the worst things you can do. When not publishing intimate information about yourself, it’s much harder to gain relevant information. In addition, there is a practice called OSINT7 that focuses on finding information based on information that is publicly available. This includes information posted on social media.
For example, in 2019 then US President Donald Trump posted an image he took with his phone showing another picture taken from a US satellite. It did not take long for the OSINT community to find the location, determine the time of the image based on shadows, and then correlated the information with satellite data. They were able to identify the exact satellite that took the image, there was just one issue. It was only possible to take said image with advanced camera systems that were at the time highly classified. presented the techniques and tools behind the investigation in a talk.
This mistake could have been avoided by either not posting anything at all or really thinking about the consequences and making a rational decision before posting. The above example might have been very extreme, but the techniques are the same for a president or a regular person.
It’s something we all know as the thing we say we read, but in reality no one reads – ever. Even if a normal person would want to read and understand the ToS8 they would have no change to understand the legal and technical talk in these documents.
Following an example from the Twitter Privacy Policy, that basically means that Twitter is storing data even after you deleted it.
If you update your public information on Twitter, such as by deleting a Tweet or deactivating your account, we will reflect your updated content on Twitter.com, Twitter for iOS, and Twitter for Android. By publicly posting content when you Tweet, you are directing us to disclose that information as broadly as possible, including through our APIs, and directing those accessing the information through our APIs to do the same.
The good thing is, that there is a project or website called tos;dr9 standing for Terms of Service; Didn’t read. This Project does read the ToS for you and then summarizes them for you to understand them. They also compose a grade that ranks services and websites based on their privacy policy.
I can recommend going through this website and getting a feeling for which page has what in their privacy policy. Going forward, I would recommend quickly checking tos;dr before signing up.
Generally, there are alternatives that promise to be more privacy focused than the service you currently are using. This section will outline what I was using before switching to said alternatives. I will outline why I chose them and why you should too. Furthermore, I will also show the limits that I have found for the alternative services.
To find the alternatives, I used a side called alternativeto.net10. It’s a crowdsourced project that collects alternatives to services and lists some of their properties, such as the license or price. For some searches a filter called Privacy Focused exists, this filter can be a good indication if a service is more privacy than others.
One of the first steps into privacy-focused services and apps was the switch from the Google Search engine to the DuckDuckGo Search engine. DuckDuckGo is an excellent alternative to Google and offers even some more features that Google does not offer, a QR Code generator for example. For about a year, I have used DuckDuckGo for almost everything in my everyday life without any issues. My initial fear of DuckDuckGo being worse when it comes to finding information about more technical things did prove it selves false. There are even cases where DuckDuckGo shows information that Google does not.
The limitation with DuckDuckGo that I missed are some Google exclusive features like the shopping feature to find the price of certain items. I also noticed that, due to a lack of tracking, DuckDuckGo is worse in showing pages that I already visited. This feature would have been useful when searching for similar things in a short period of time.
I would describe the switch from Android11 to GrapheneOS12 as the most radical step to a more privacy in the digital word. GrapheneOS is based on the same code as other Android devices are. That means GrapheneOS runs all Apps that work on any other Android phone. GrapheneOS is a so called DeGoogled phone, meaning that all Google services are either restricted or removed.
To run a phone with GrapheneOS, some technical knowledge is needed. Since there are no phones that ship with GrapheneOS, every user has to install it by themselves. That involves a multistep process that goes way deeper than any regular user would understand. However, the work pays out. I got a phone with absolutely no tracking software from any companies, including Google or other Bloatware13.
With almost everything in privacy, there also was a bigger trade off with the increase in privacy. For example, before using GrapheneOS, I used to pay everything with my phone using Google Wallet14. Unfortunately, this is not possible anymore due to a lack of Google Software on my phone.
The vision with a phone that uses absolutely no Google Services was not possible for me because so many apps including banking apps or simple Notifications from apps require Google Services. I installed the Google Services with fewer permissions, so they don’t have unlimited access to things to information about my phone. This way I am able to use Google Services like YouTube without any issues and less tracking by the App it selves.
In dieser Arbeit konnte ich mich hervorragend mit dem Thema auseinandersetzen und eine Faszination für das Thema aufrecht halten. Dies hat es mir ermöglicht, dass ich immer wider etwas Neues gelernt habe. Ich habe aber nicht nur technisch viel Neues gelernt. Zum ersten Mal habe ich mit LaTeX eine Arbeit geschrieben. In den Interviews konnte ich viel lernen, wie andere denken und was deren Sicht auf meine Themen sind. Ich habe auch das Gefühl, dass ich ihre Gedanken gut in die Arbeit einbringen konnte.
Ich konnte auch einige meiner Ansichten überarbeiten oder verstärken. Ein Argument, das gemacht wurde, dass nicht die Plattformen wie TikTok oder Instagram Schuld tragen, wenn private Informationen veröffentlicht werden, sondern die Nutzer selbst ist etwas, wo ich uneingeschränkt zustimmen kann.
Über die gesamte Arbeit hatte ich Probleme, meine vielen Gedanken und Überlegungen in Textform zu bringen. Viele Konzepte, die ich in einer Präsentation einwandfrei umsetzten, kann, kann man nicht umsetzten in der geschriebenen Form. Da hat es sich gezeigt, dass ich nicht allzu viel schreibe, dafür sehr viel präsentiere. Auch habe ich den Aufwand unterschätzt, eine Analyse meiner Google Daten zu erstellen und diese in die Arbeit einfliessen zu lassen. Daher habe ich nicht allzu viel, bis auf zwei Grafiken, in diese Arbeit einfliessen lassen. Mein Ziel ist es zur Präsentation die Auswertung bereitzuhaben.
Auch hatte ich Probleme damit, meine Arbeit so zu formulieren, dass sie von weniger technisch versierten Menschen verstanden werden kann. Dies war mir wichtig, um ein grösseres Zielpublikum zu erreichen.
Ich bedanke mich bei
SciHub für den Zugang zu gewissen Papern.
LanguageTool für die Rechtschreib- und Grammatikprüfung
ETH für die Bereitstellung des genutzten Templates 15
meinen Interviewpartnern für ihre Gedanken und Ansichten
Alternative.to für die Aufzeigung von Alternativen
TOS;DR für die verständliche Aufarbeitung von Privatsphäre Regelungen
GrapheneOS für die Möglichkeit ein Privates Online leben zu führen.
Die IMEI Nummer beschreibt einzigartige Identifikations-Nummern für jeden SIM Karten Slot↩︎
Hochauflösende Versionen sind auf https://va.lorispolenz.com zu finden↩︎
z. B. Samsung, Xiaomi oder Oppo↩︎
Extern geladener Code↩︎
Die Sammlung von Nutzerdaten ohne deren Zustimmung↩︎
https://divviup.org↩︎
Open-Source Intelligence↩︎
Terms of Sercice↩︎
https://tosdr.org↩︎
https://alternativeto.net↩︎
Android in this case describes the Android installed by default on phones↩︎
https://grapheneos.org/↩︎
Describes preinstalled Software that is useless↩︎
A service from Google to store and use payment cards↩︎
https://shorturl.at/bnIQ5↩︎